Dear Suzuki,
Please do the needful.
Regards,
Balraj Balakrishnan
Assistant Manager – IRL
Integra Software Services Pvt. Ltd.
100 Feet Road, ECR, Pondicherry-605008
Phone: +91 413 4212124 x 321
Mobile: +91 9842385151
Life is a one way journey, not a destination. Travel it with a smile and never regret anything. Yesterday is history, tomorrow is a mystery, today
is gift - that’s why we call it present.
This email and any accompanying attachments is for the sole use of the intended recipient(s) and may contain confidential and privileged information. Any unauthorized review, use,
disclosure, distribution, or copying is strictly prohibited. If you are not the intended recipient of this communication or received the email by mistake, please notify the sender and destroy all copies. Integra Software Services Pvt Ltd. reserves the right,
subject to applicable local law, to monitor and review the content of any electronic message or information sent to or from its company allotted employee email address/ID without informing the sender or recipient of the message.
From: Balraj Balakrishnan, Integra-PDY,
IN
Sent: 02 May 2011 14:50
To: 'address@hidden'
Cc: address@hidden; address@hidden
Subject: RE: [ft] FW: Getting the charcode Value when the Glyph ID is known
Dear Suzuki,
As am new to freetype and all these font stuffs, I couldn’t rather frame my requirement in a right manner. I shall be making an another attempt to bring about much more clarity in what I really want from freetype:
1.
The scenario here is, we are trying to convert the source PDF into an HTML, while doing this there are many fonts in the PDF which are extracted or mapped to a wrong character. So we are extracting the font files from the PDF, to convert
glyph's (Symbols, Unicode) in the font file as an image and replace the wrongly extracted characters/Symbols/Unicode in the HTML file with the image.
In the above mentioned scenario the image should maintain its position in the outline in order place it in an HTML file. If you look at the image below the fonts Quote right and the Comma is differentiated
based on its position in a given line.
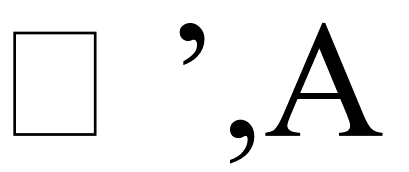
So what I am trying to achieve is to extract an image with its rectangular boundary intact, it shouldn’t be cropped for white spaces as shown below:

![]()
2.
>Can you help me with other alternatives which are there to iterate all the glyphs present in the font file irrespective of the cmap table.
You can get the maximum glyph index from FT_Face->num_glyphs.
Scanning like
for ( gid = 0; gid < face->num_glyphs; gid ++ )
{
How to get the character code for a particular gid if available?
}
Be Well,
Amith Sai
-----Original Message-----
From: address@hidden [mailto:address@hidden
Sent: 30 April 2011 01:00
To: Balraj Balakrishnan, Integra-PDY, IN
Cc: address@hidden; address@hidden
Subject: Re: [ft] FW: Getting the charcode Value when the Glyph ID is known
On Fri, 29 Apr 2011 12:01:54 +0000
"Balraj Balakrishnan, Integra-PDY, IN"
<address@hidden> wrote:
>How can I achieve the glyph image with its proper positioning, in order
>to tackle this scenario?
Sorry, I could not understand it from your message, what is
your scenario? You want to do something like OCR?
>Can you help me with other alternatives which are there to iterate all
>the glyphs present in the font file irrespective of the cmap table.
You can get the maximum glyph index from FT_Face->num_glyphs.
Scanning like
for ( gid = 0; gid < face->num_glyphs; gid ++ )
{
/* blah blah blah */
}
is very popular in various softwares using FT2.
Regards,
mpsuzuki