[Top][All Lists]
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: GUILE_MAX_HEAP_SIZE
|
From: |
Han-Wen Nienhuys |
|
Subject: |
Re: GUILE_MAX_HEAP_SIZE |
|
Date: |
Tue, 19 Aug 2008 12:46:31 -0300 |
|
User-agent: |
Thunderbird 2.0.0.16 (X11/20080723) |
Ludovic Courtès escreveu:
>> Ludovic Courtès escreveu:
>
>> Can you be more specific about this?
>
> Off the top of my head: incorrect indentation, missing spaces around
> brackets, and more importantly comments (see (standards.info)Comments).
The code I went through should not have that; please point me to locations
where things are broken so I can fix them.
>> See below - note that the old .scm file was pretty much broken, as it
>> was using gc-live-object-stats which is only accurate just after the
>> mark phase.
>
> Hmm, `gc-live-object-stats' may return information from the previous
> cycle, but it shouldn't be *that* accurate, should it?
No; the current implementation uses a similar scheme to
gc-live-object-stats (counting in the bitvector) to determine the live
object count. There is now no way that it can ever be larger than the
total heap size.
I also changed the code to not look at the penultimate GC stats, since
I couldn't invent a scenario where that would help, and IMO it only
confuses things. This may have been a remnant of the pre-lazy sweep
code.
> Interestingly, head-before-your-changes and 1.8 end up with
> `cells-allocated' greater than `total-cell-heap', which I guess isn't
> intended (`cells-allocated' and `scm_cells_allocated' are really the
> total number of cells allocated since the last GC, right?). In the case
> of 1.8, it's only slightly greater; in the case of
> head-before-your-changes, it's more than 80 times greater. That does
> seem to indicate brokenness...
There was some confusion about cells vs. double cells vs. bytes, but I
think was mostly in my head and perhaps in your stress test.
If you really want to know, use git bisect.
A likely candidate is the patch from you that I applied. In
particular,
4c7016dc06525c7910ce6c99d97eb9c52c6b43e4
+
+ seg->freelist->collected += collected * seg->span;
looks fishy as this code is called multiple times for a given
card.
>> The problem is that the previous state of the GC was very much confused
>> with contradicting definitions within the code of what was being kept as
>> statistics. This is problematic since the allocation strategy (should
>> I allocate more memory?) was based on these confused statistics.
>
> Which statistics were confused exactly? Can you pinpoint the part of
> your patch that fixes statistics computation? Otherwise, I find it hard
> to say whether it's actually "fixed".
The scm_t_sweep_statistics were sometimes passed into the sweep
function and sometimes not; I couldn't work out what the global
variables were supposed to mean exactly, and consequently, if their
updates were correct. The reason I am confident about the statistics
now is the assert()s I added to scm_i_gc(), which compare exactly mark
bit counts, the sweep statistics and freelist statistics. Some of the
changes I did were to make these numbers match up exactly.
>> It's still somewhat kludgy - especially the way that gc-stats is
>> constructed is asking for trouble. We should really have a scm_t_gc_stats
>> struct and use nice OO patterns for dealing with that.
>
> What would you think of using the Boehm et al. GC?
>
> I'm willing to import the BGC-based Guile branch into Git when time
> permits, so that we can compare them.
I think we've tried this before, and IIRC it was 50~100% performance
hit. Of course we could try again, but since we have a much better
understanding of data is laid out, we can be faster.
Unfortunately I don't have time to look into this, but we also be
compact the heap (Bartlett's patents have or are soon to be expired).
I'd be interested in seeing benchmarks between Guile and PLT after my
cleanup. For a lot of benchmarks, GC time is an important factor, and
it might be that we can now beat PLT (they use BGC).
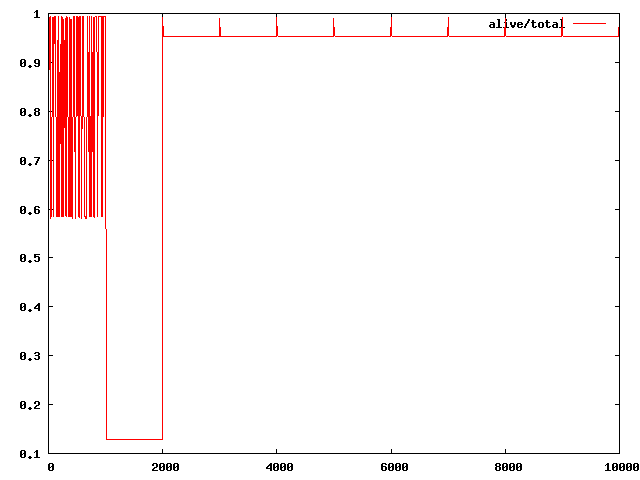
BTW, I'm attaching a new plot of the stress test, now up to iteration
10000 (the large allocation). Interestingly, the large allocation is
cleaned up only once - (on iteration 1000), and remains 'live' after
that, so there may still be some bugs lurking.
BTW2 stress.scm says
(char-set #\.) ;; double-cell
char-sets are smobs and use single cells, AFAICT.
--
Han-Wen Nienhuys - address@hidden - http://www.xs4all.nl/~hanwen
- Gnulib files now in the repository, (continued)
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/15
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/15
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/17
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/19
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/19
- Re: GUILE_MAX_HEAP_SIZE,
Han-Wen Nienhuys <=
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/21
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/21
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/21
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/22
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/21
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/22
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Ludovic Courtès, 2008/08/18
- Re: GUILE_MAX_HEAP_SIZE, Han-Wen Nienhuys, 2008/08/19