Hi Peter and Nick,
Thank you for the suggestions and performance findings. We rebuilt with ILMBASE_FORCE_CXX03 defined, however the write speed changes remain unchanged . We’ll look at your suggestions too Peter and will also take a peak with vtune.
Regards,
Tony
From: Peter Hillman <address@hidden>
Date: Wednesday, 3 April 2019 at 07:30
To: Nick Porcino <address@hidden>, Tony Micilotta <address@hidden>, "address@hidden" <address@hidden>
Subject: Re: [Openexr-devel] OpenExr 2.3 - slower write speeds for Uncompressed and Zip1
I've just been running tests myself along the same lines.
I tried comparing writing various schemes with EXR-2.2.1, EXR-2.3.0 and EXR-2.3.0 using an IlmBase build with ILMBASE_FORCE_CXX03 (passing --enable-stdcxx=03 to ./configure)
This attempts to use the API in a similar way to the Nuke exrWriter example (my code attached)
Conclusions:
I don't think ILMBASE_FORCE_CXX03 has a difference in my test.
I find no reliable speed difference between 2.2.1 and 2.3.0 where no threadpool is used (so running the attached test using testEXR zips none 1 /tmp/test.exr) or the number of threads is close to the number of CPU cores regardless of compression scheme (e.g. with 4 cores try testEXR zips 4 20 /tmp/test.exr) .
I did manage to make 2.3.0 go slower than 2.2.1, by running testEXR zips 100 10 /tmp/test.exr which means there are 100 threads allocated, but only a (random?) 10 of those have anything to do each time, since only 10 scanlines are written at once, and those 10 are fighting for (in my case) 4 cores. Both 2.2.1 and 2.3.0 run slower with excessive threadpools, but the effect is significantly more in 2.3.0.
I wonder if somehow Nuke's other threads are interfering with EXRs threadpool operation in 2.3.0 in a way they aren't in 2.2.1? It might be interesting to implement a test like the attached as a self-contained method triggered from a button press in a Nuke node, so it runs within Nuke's existing framework but doesn't use any Nuke functionality at all, and see if there's a difference between that and running the function as a standalone binary outside of Nuke.
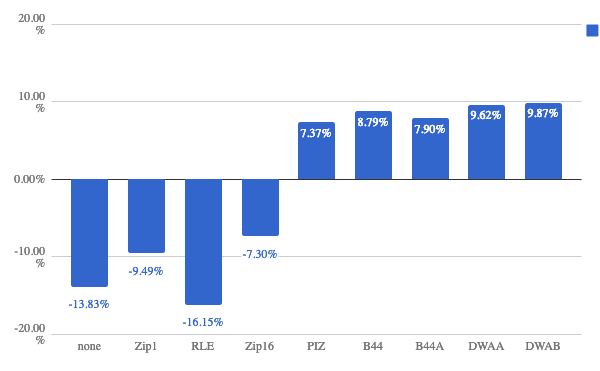
I'm intrigued that, according to the graph, the compression schemes that write single scanlines at once have slowed down, and the ones that write many scanlines at once have sped up. Schemes that write multiple scanlines per block have lower overhead through IlmThread. In my case I didn't see any significant speedups with 2.3.0 in any scheme.
Peter
From: Openexr-devel <openexr-devel-bounces+peterh=address@hidden> on behalf of Nick Porcino <address@hidden>
Sent: Wednesday, 3 April 2019 5:05 PM
To: Tony Micilotta; address@hidden
Subject: Re: [Openexr-devel] OpenExr 2.3 - slower write speeds for Uncompressed and Zip1
One of the big differences between 2.2 and 2.3 is that we moved from pthread to std::thread, and made a number of corrections for thread safety.
e.g.
https://github.com/openexr/openexr/commit/eea1e607177e339e05daa1a2ec969a9dd12f2497
https://github.com/openexr/openexr/commit/bf0cb8cdce32fce36017107c9982e1e5db2fb3fa
The old pthread/windows native implementation can be re-enabled by setting the preprocessor define ILMBASE_FORCE_CXX03. I am wondering if you might be able to benchmark against that version of the code as an experiment to get more information?
From: Openexr-devel <openexr-devel-bounces+meshula=address@hidden> on behalf of Tony Micilotta <address@hidden>
Sent: Monday, April 1, 2019 8:27:29 AM
To: address@hidden
Subject: [Openexr-devel] OpenExr 2.3 - slower write speeds for Uncompressed and Zip1
Hi,
At Foundry we’ve started testing the read performance of OpenExr 2.3 with Boost 1.66 as we move Nuke towards conforming to VFX Reference Platform 2019. Although the release notes don’t mention any changes to file writing, we have charted (see graphic below) OpenExr 2.3 write performance against OpenExr 2.2 as we noticed a slowdown in our playback cache generation which uses OpenExr.
From Nuke, a checkerboard/colourwheel combination is generated and animated over 100 frames in order to eliminate file reading from the measurements. These 100 frames are written to disk using each compression type, and the timings are averaged over 10 test runs. Certain compression types show an improvement which is great, however we’re concerned that Uncompressed and Zip1 are 13% and 9% slower respectively:
Have you benchmarked this on your side too, and have you noticed similar metrics?
Regards,
Tony
Tony MicilottaSenior Technical Product Manager - Nuke Family
Tel: +44 (0)20 7479 4350
Web: www.foundry.com
The Foundry Visionmongers Ltd. - Registered in England and Wales No: 4642027 - Address: 5 Golden Square, London, W1F 9HT - VAT No: 672742224